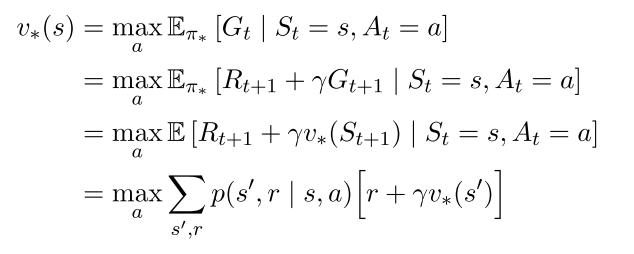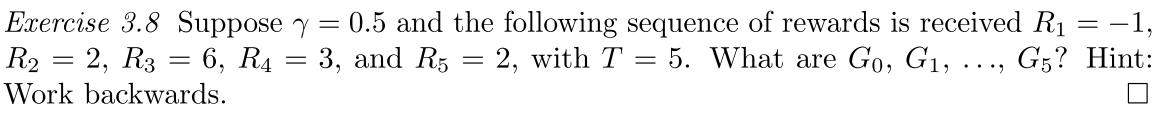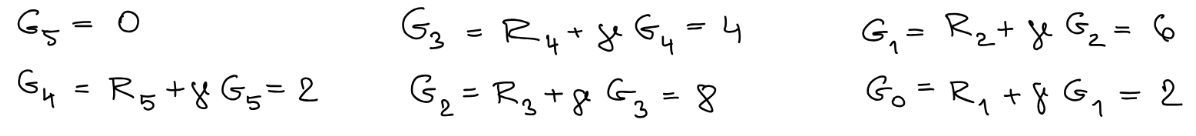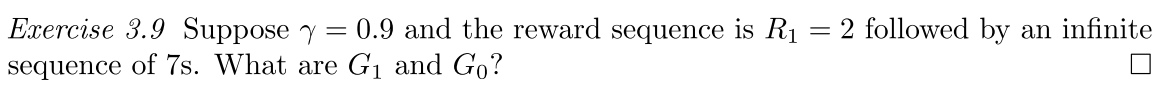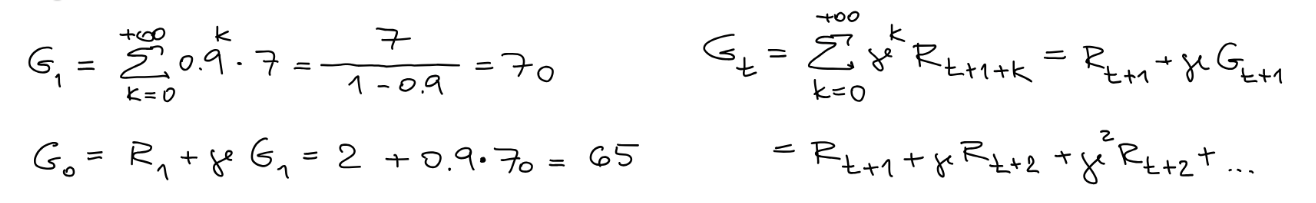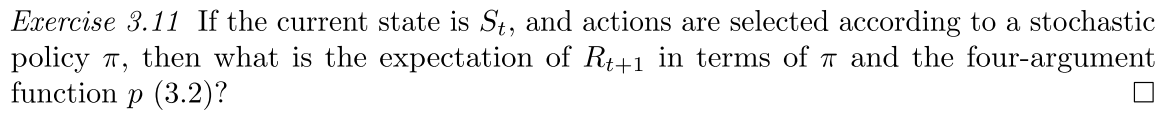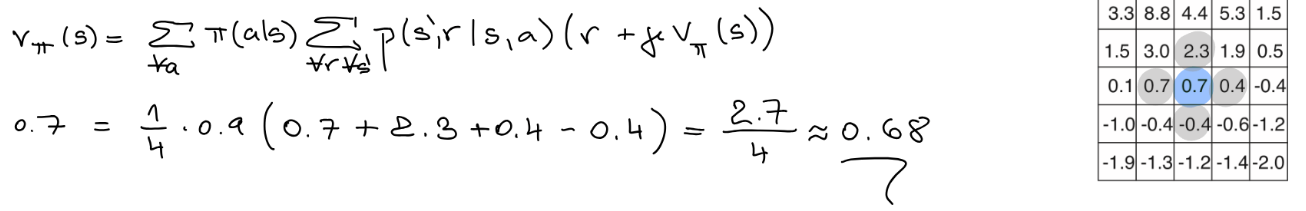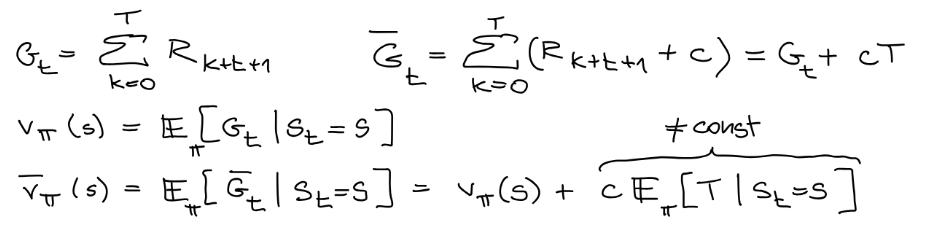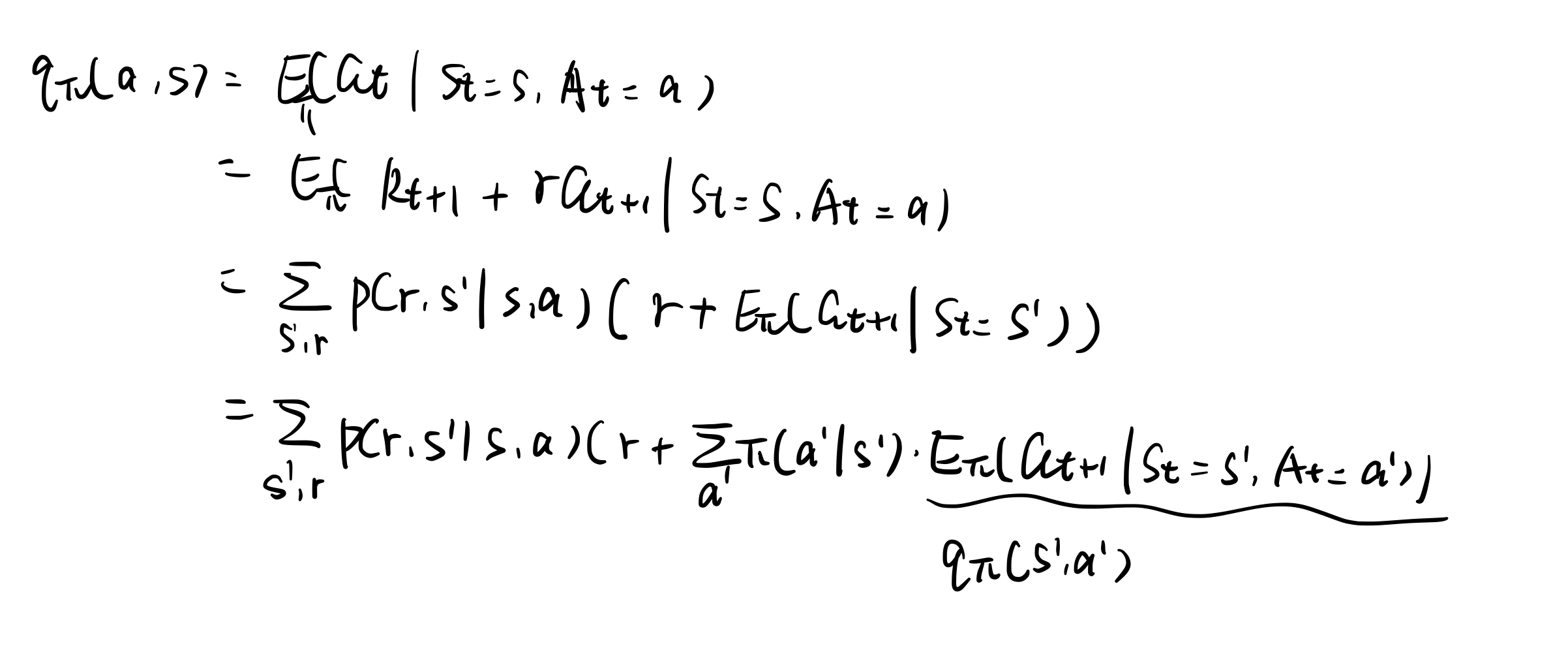Our goal is not maximising immediate reward but cumulative rewards, which can be called as return.
表示在时刻t所获得的奖励reward, 表示从 t 时刻状态 开始一直到终止,所有的奖励之和称之为 return
Typically we use discounted return:$$G_{t}=R_{t+1}+\gamma R_{t+2}+\gamma^{2}R_{t+3}+\ldots=\sum_{i=0}^{\infty}\gamma^{i}R_{t+i+1}$$
Why we use discounted return?
it's used to handle the trade-off between immediate rewards and future rewards.
Preference for Immediate Rewards: immediate rewards are considered more valuable than future rewards, so we use discounted rewards to weaken the impact future on the present.
Infinite Horizon Problems: some MDPs have infinite steps while return will be also infinite without discounted rate.
We can express in terms of future returns:
Although it is a sum of an infinite number of terms, it's still finite if the reward is nonzero and constant while $$G_{t}=\sum_{k=0}^{\infty}\gamma^{k}={\frac{1}{1-\gamma}}$$
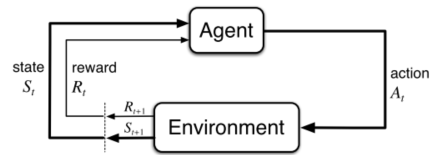
A policy g is a strategy that the agent uses to decide which action to take at each state which means a mapping from states to actions.
Almost all reinforcement learning use value-funtion/ state-value function to estimate how good the policy is. And how good is defined in terms of expected returns.
Deterministic Policy: A deterministic policy provides a specific action for each state. This can be represented as: $$a = \pi(s)$$This formula means that, given state , the policy will always choose action .
Stochastic Policy: A stochastic policy provides a probability distribution over possible actions for each state. This can be represented as:$$\pi(a\mid s)=\operatorname*{Pr}\left{A_{t}=a\mid S_{t}=s\right}$$
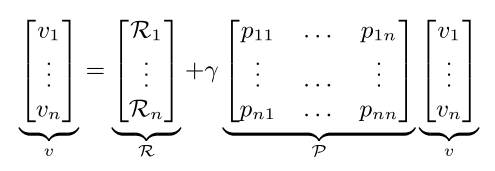
Value function
分为两种 state value function and action value function
value: 一个状态的期望回报(即从这个状态出发的未来累积奖励的期望)被称为这个状态的价值。
value function: 所有状态的价值就构成了价值函数。输入为某个状态,输出这个状态对应的价值。
Now it changes to a episode task not a continue task, we could calculate the new value function as followed:This means every new state value function will not add a same constant term rather term with respect to episode length T.
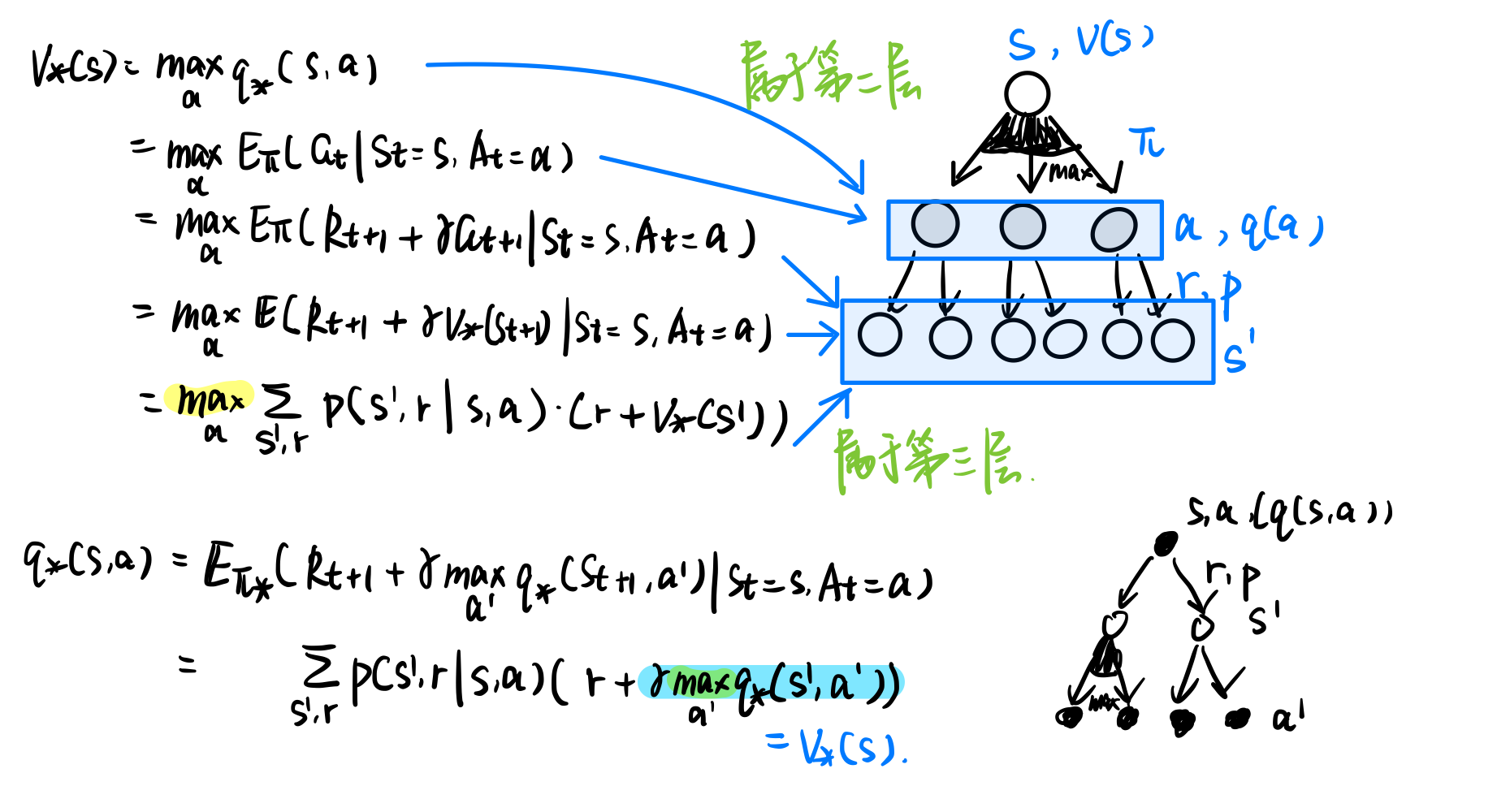
is probabilistic policy that is greedy, is a deterministic policy, prove for all state s